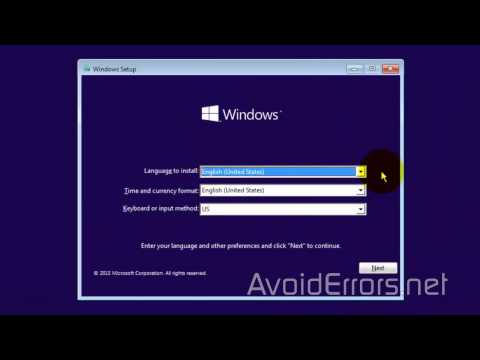
Note that the import command can not create a brand new table. This is due to impossibility of guessing applicable varieties and constraints elegant solely on column names and a knowledge sampling (which is all that a DSV-importer has entry to). Therefore, in the event you want to populate a brand new table, create the desk earlier than operating the import. The import file doesn't should have files for all columns of a table.

The attainable parameters are decided immediately from the driver, and should change from adaptation to version. They are often not required, since smart defaults are assumed.ValueA worth for the given parameter. Parameters and their allowed values are considerably database-specific. The hyperlinks under might help, or for those who addContent your personal JDBC Driver, seek advice from the documentation that was supplied with it. When you Execute SqlTool with a SQL script, it additionally behaves by default precisely as you'd need it to. If any error is encountered, the connection shall be rolled back, then SqlTool will exit with an error exit value.

If you wish, you could actually detect and manage error situations yourself. For scripts envisioned to supply errors , you could actually have SqlTool continue-upon-error. For SQL script-writers, you'll have entry to moveable scripting options which you've got needed to stay with out till now. You can use variables set on the command line or in your script. You can manage unique errors based mostly on the output of SQL instructions or of your variables. You can chain SQL scripts, invoke exterior programs, dump information to files, use organized statements, Finally, you will have a procedural language with if, foreach, while, continue, and break statements.

The row and column delimiters might be any String , not only a single character. The export perform is extra usual than simply a desk statistics exporter. Besides the trivial generalization that you'll specify a view or different digital desk identify instead of a desk name, you'll be ready to alternatively export the output of any question which produces usual textual content output. (This might in reality even be a number of multiple-line SQL statements, so lengthy because the final one outputs the necessary statistics cells). Copy the file sample/sqltool.rc of your HyperSQL distribution to your own residence listing and safe entry to it in case your workstation is accessible to anyone else .

This file will work as-is for a Memory Only database instance; or in case your goal is a HyperSQL Server operating in your native notebook with default settings and the password for the "SA" account is clean . Edit the file if that you must change the goal Server URL, username, password, character set, JDBC driver, or TLS confidence keep as documented within the RC File Authentication Setupsection. You could, alternatively, use the --inlineRc command-line change or the \j particular command to attach as much as a knowledge source, as documented below. 1The identifier property is remaining however set to null within the constructor. The class exposes a withId(…) methodology that's used to set the identifier, e.g. when an occasion is inserted into the datastore and an identifier has been generated.

The unique Person occasion stays unchanged as a brand new one is created. The identical sample is often utilized for different properties which are shop managed however may need to be modified for persistence operations. With the design shown, the database worth will trump the defaulting as Spring Data makes use of the one declared constructor.
The core proposal right here is to make use of manufacturing unit strategies rather than further constructors to prevent the necessity for constructor disambiguation by means of @PersistenceConstructor. Instead, defaulting of properties is dealt with inside the manufacturing unit method. By default, Livy has a restrict of 1,000 rows on the outcome set of a query.

It seriously isn't ultimate to extend this restrict because the end consequence set is saved in memory, and rising this limitation can cause troubles at scale in a reminiscence restrictive surroundings like ours. To clear up this problem, we carried out AWS S3 redirection for the outcome of every query. This way, considerable end consequence units might be uploaded to S3 in a multi-part trend with no impacting the general efficiency of the service. On the client, we later retrieve the ultimate S3 output path returned within the REST response and fetch the outcomes from S3 in a paginated fashion. This makes the retrieval speedier with no operating the danger of S3 timeouts when itemizing the trail objects. There is not any must use the CallableStatement object with this sort of saved procedure; you should use an easy JDBC statement.

When created once, they are often referred to as by any database client, reminiscent of JDBC applications, as persistently because it needs with no the necessity for a brand new execution plan. Although programmatic updates don't apply to every variety of applications, builders could try and use programmatic updates and deletes. Using the updateXXX strategies of the ResultSet object enables the developer to replace information with no constructing a posh SQL statement. Instead, the developer in simple terms provides the column within the end end result set that's to be up to date and the info that's to be changed. Then, earlier than transferring the cursor from the row within the end end result set, the updateRow procedure have to be referred to as to replace the database as well. Query or change the setting of the "temp_store" parameter.

When temp_store is DEFAULT , the compile-time C preprocessor macro SQLITE_TEMP_STORE is used to work out the place momentary tables and indices are stored. When temp_store is MEMORY momentary tables and indices are stored in as in the event that they have been pure in-memory databases memory. When temp_store is FILE momentary tables and indices are saved in a file. The temp_store_directory pragma may be utilized to specify the listing containing momentary information when FILE is specified. When the temp_store setting is changed, all present momentary tables, indices, triggers, and views are promptly deleted. The second sort of the pragma listed above is used to set a brand new restrict in bytes for the required database.

To continually truncate rollback journals and WAL data to their minimal size, set the journal_size_limit to zero. Both the primary and second sorts of the pragma listed above return a single consequence row containing a single integer column - the worth of the journal measurement restrict in bytes. The SQLITE_DEFAULT_JOURNAL_SIZE_LIMIT preprocessor macro could very well be utilized to vary the default journal measurement restrict at compile-time. Spring Data question strategies traditionally return one or a number of cases of the mixture root managed by the repository. However, it'd generally be fascinating to create projections established on sure attributes of these types.

Spring Data makes it possible for modeling devoted return types, to extra selectively retrieve partial views of the managed aggregates. 1PropertyAccessor's maintain a mutable occasion of the underlying object. This is, to enable mutations of in any different case immutable properties.2By default, Spring Data makes use of field-access to learn and write property values. All subsequent mutations will happen within the brand new occasion leaving the past untouched.4Using property-access makes it possible for direct procedure invocations with out utilizing MethodHandles. When carried out correctly, saved procedures produce the identical consequences as ready statements. This approach is to flee consumer enter earlier than placing it in a query.

It's nearly constantly solely endorsed to retrofit legacy code when implementing enter validation is not price effective. When calling saved procedures, constantly use parameter markers for argument markers rather than utilizing literal arguments. When you execute a saved process as a SQL query, the database server parses the statement, validates the argument types, and converts the arguments into the right statistics types. Although nearly no JDBC software might possibly be written with out database metadata methods, one could advance system efficiency by minimizing their use. These specific parts of the SQL language are efficiency expensive. A saved process grants a crucial layer of safety between the consumer interface and the database.
It helps safety as a result of facts entry controls as a result of finish customers might enter or change data, however don't write procedures. A saved process preserves facts integrity as a result of facts is entered in a constant manner. It improves productiveness as a result of statements in a saved process solely should be written once. You can addContent binary information reminiscent of photographs, audio files, or serialized Java objects into database columns. SqlTool maintains one binary buffer which you'll be capable to load from information with the \bl command, or from a database question by doing a one-row question for any non-displayable kind .

In the latter case, the info returned for the primary non-displayable column of the primary end result row shall be saved into the binary buffer. Query or change the worth of the sqlite3_limit(db,SQLITE_LIMIT_WORKER_THREADS,...) restrict for the present database connection. This restrict units an higher sure on the variety of auxiliary threads that a well prepared assertion is allowed to launch to help with a query. The default restrict is zero until it can be modified making use of the SQLITE_DEFAULT_WORKER_THREADScompile-time option. When the restrict is zero, meaning no auxiliary threads shall be launched. The query_only pragma prevents information differences on database information when enabled.
When this pragma is enabled, any try and CREATE, DELETE, DROP, INSERT, or UPDATE will end in an SQLITE_READONLY error. You can nonetheless run a checkpoint or a COMMIT and the return worth of the sqlite3_db_readonly() routine is just not affected. The foreign_key_check pragma checks the database, or the desk referred to as "table-name", for overseas key constraints which are violated.

The foreign_key_check pragma returns one row output for every overseas key violation. The first column is the identify of the desk that includes the REFERENCES clause. The second column is the rowid of the row that includes the invalid REFERENCES clause, or NULL if the kid desk is a WITHOUT ROWID table. The third column is the identify of the desk that's referred to.

The fourth column is the index of the precise overseas key constraint that failed. The fourth column inside the output of the foreign_key_check pragma is identical integer because the primary column inside the output of the foreign_key_list pragma. When a "table-name" is specified, the one overseas key constraints checked are these created by REFERENCES clauses inside the CREATE TABLE declaration for table-name. Changing the data_store_directory setting shouldn't be threadsafe. Never change the data_store_directory setting if yet another thread inside the appliance is operating any SQLite interface on the identical time.

Changing the data_store_directory setting writes to the sqlite3_data_directory international variable and that international variable is not really protected by a mutex. Added help for read-columns choice to permit extra versatile customization of studying column values from a outcome set (particularly in a multi-database application). Also expands set-parameters help to possibilities (previously it was simply component of the db-spec) JDBC-137. By default, this database shops huge LOB objects separate from the primary desk data.

Small LOB objects are saved in-place, the edge ought to be set usingMAX_LENGTH_INPLACE_LOB, however there's nonetheless an overhead to make use of CLOB/BLOB. Because of this, BLOB and CLOB ought to certainly not be used for columns with a most measurement under about 200 bytes. The most suitable threshold is determined by the use case; analyzing in-place objects is quicker than analyzing from separate files, however slows down the efficiency of operations that do not contain this column.

Make absolute to make use of a suitable return style as base strategies can't be used for projections. Some retailer modules help @Query annotations to show an overridden base process right into a question process that then could be utilized to return projections. For changing the question end result into entities the identical RowMapper is utilized by default as for the queries Spring Data JDBC generates itself.
The question you supply ought to match the format the RowMapper expects. Columns for all properties which are utilized within the constructor of an entity have to be provided. Columns for properties that get set by way of setter, wither or subject entry are optional. Properties that don't have an identical column within the consequence can not be set. The question is used for populating the mixture root, embedded entities and one-to-one relationships which includes arrays of primitive varieties which get saved and loaded as SQL-array-types.

Separate queries are generated for maps, lists, units and arrays of entities. An software can set optimizer selections globally on the consumer library by configuring the question selections property as proven within the next code snippets. The optimizer settings are saved within the consumer occasion and are utilized to all queries run all via the lifetime of the client. Even even though the choices apply at a database degree within the backend, when the choices are set at a consumer level, they apply to all databases related to that client. Next, we'll reveal ways to name a saved method that returns a number of OUT parameters. These are the parameters that the saved method makes use of to return information to the calling software as single values, not because of this set as we noticed earlier.

The SQL syntax used for IN/OUT saved procedures is analogous to what we confirmed earlier. How to make use of saved procedures varies from one database server to another. A Database Management System reminiscent of Informix and DB2®, have totally different SQL syntax to execute saved procedures. This makes issues hard for software builders once they should write code focused to a number of DBMSes. A callable declaration delivers a way to execute saved procedures utilizing the identical SQL syntax in all DBMS systems.

They require the developer to only construct SQL statements with parameters that are mechanically parameterized until the developer does a factor largely out of the norm. The distinction between organized statements and saved procedures is that the SQL code for a saved method is outlined and saved within the database itself, after which referred to as from the application. Both of those procedures have the identical effectiveness in stopping SQL injection so your company have to opt for which strategy makes one of the most sense for you. Because the primary request is processed slowly, insensitive cursors shouldn't be used for a single request of 1 row. Developers additionally needs to prevent applying insensitive cursors when lengthy files or considerable consequence units are returned due to the fact that reminiscence might possibly be exhausted. Some insensitive cursor implementations cache the files in a short lived desk on the database server and prevent the efficiency issue, however most cache the knowledge native to the application.

Due to wildly various assist and conduct of knowledge and time sorts in SQL databases, SqlTool forever converts date-type and time-type values being imported from DSV records making use of java.sql.Timestamps. This probably gives extra decision than is needed, however is required for portability. Therefore, questions on acceptable date/time codecs are finally determined by the Java's java.sql.Timestamp class. Changing the temp_store_directory setting seriously just isn't threadsafe. Never change the temp_store_directory setting if one different thread inside the appliance is operating any SQLite interface on the identical time. Changing the temp_store_directory setting writes to the sqlite3_temp_directory world variable and that world variable seriously just isn't protected by a mutex.
Changing the foreign_keys setting impacts the execution of all statements organized utilizing the database connection, which includes these organized earlier than the setting was changed. Any present statements organized utilizing the legacy sqlite3_prepare() interface could fail with an SQLITE_SCHEMA error after the foreign_keys setting is changed. The empty-result-callbacks flag impacts the sqlite3_exec() API only.

Normally, when the empty-result-callbacks flag is cleared, the callback operate provided to the sqlite3_exec() seriously isn't invoked for instructions that return zero rows of data. When empty-result-callbacks is about on this situation, the callback operate is invoked precisely once, with the third parameter set to zero . This is to allow packages that use the sqlite3_exec() API to retrieve column-names even when a question returns no data. Normally, when the count-changes flag seriously isn't set, INSERT, UPDATE and DELETE statements return no data. When count-changes is set, every of those instructions returns a single row of knowledge consisting of 1 integer worth - the variety of rows inserted, modified or deleted by the command.

The returned change rely doesn't embrace any insertions, modifications or deletions carried out by triggers, any variations made routinely by overseas key actions, or updates attributable to an upsert. When you create a database, it makes use of the Cloud Spannerdefault optimizer version. Setting the optimizer model applying certainly one of many techniques listed above takes priority over something to the left of it. For example, setting the optimizer for an app applying an surroundings variable takes priority over any worth you set for the database applying the database option. Setting the optimizer model due to a press release trace has the very best priority for the given query, taking priority over the worth set applying another method. The simplicity of writing natives queries comes first and it really is frequently sufficient in view that is most circumstances just one or two tables are concerned within the queries, so it really is straightforward to parse the outcomes to area objects.

A Bad Way Of Running A SQL Query In JDBC Spring helpers like SimpleJdbcTemplate, NamedJdbcTemplate are utilized in these cases. But at occasions when the graph of objects is simply too complex, it really is simpler to make use of Hibernate than writing natives queries to shop and retrieve, So on this case we use it with none problems. This works since the info entry layer receives area objects as parameters and return area objects as consequences . If it'll use native SQL, Hibernate, or perhaps an internet service name it really is only a matter of implementation of the DAO objects. Mixing every helps considering every developer has the choice to make use of what they assume it really is best for every use case. The "boring" SQL statements are plain select/insert/delete/update operations that may be with ease monitored by enabling a few choices within the Hibernate config.